一直以來,Google 對於自身演算法的運作方式始終保持著高度的保密性,只透露一些籠統的資訊,讓許多 SEO 從業者感到困惑和沮喪。只能依靠推測和經驗,不斷試驗不同的策略,希望能找到SEO成功的秘訣。
然而,近日一批 Google 內部文件意外外洩,揭露了 Google 演算法的深層秘密。這次事件,猶如一顆重磅炸彈,震撼了整個 SEO 產業。它不僅證實了 Google 在過去對許多的說法都是謊言,更讓我們得以一窺 Google 搜尋系統的內幕。
接下來,我們將深入探討由知名SEO權威,Mike King 對外洩文件的詮釋,揭開搜尋演算法的秘密。
揭露 Google 的謊言
多年來,Google 一直以「透明」和「公開」的姿態面對外界,但事實上,他們卻在許多關鍵的”最佳做法”法上,對外散布了錯誤的資訊,甚至進行了有意的誤導。這次的外洩文件,如同揭開了 Google 的神秘面紗,將這些謊言赤裸裸地展現於世人眼前。
網域權威的謊言
Google 經常聲稱他們沒有使用「網域權威」這個指標,而將其歸類為第三方平台所創造的指標,例如 Moz 的 Domain Authority 、Ahrefs 的 Domain Rating 。然而,外洩文件中卻明確表示 Google 內部存在一個被稱為「siteAuthority」的指標,它實際上是對網域權威的計算。這意味著 Google 一直都在秘密使用這項內部指標,而他們過去的說法只不過是掩蓋真相的煙霧彈。
點擊數據
Google 曾多次強調他們不使用點擊數據進行排名,但真相卻是他們擁有一個稱為「NavBoost」的系統,這個系統正是利用點擊數據來調整排名。
NavBoost 透過分析使用者的點擊行為,例如點擊時間、點擊順序、點擊深度等,來判定網頁的品質,進而影響其在搜尋結果中的排名。這項證據明確地證明了 Google 過去關於不使用點擊數據的說法是假的。
沙盒不存在的謊言
Google 一直堅稱搜尋結果中不存在「沙盒」,也就是將新的或低信任度的網站隔離的機制。然而,外洩文件揭露了一個稱為「hostAge」的指標,它實際上被用於對新網站進行「沙盒處理」。這意味著 Google 確實存在沙盒機制,只是他們選擇隱瞞事實。
隱瞞使用 Chrome 的數據
Google 宣稱他們沒有使用 Chrome 瀏覽器數據進行排名,但事實並非如此。外洩文件中顯示,Google 使用 Chrome 瀏覽器數據來評估頁面品質以及網站連結。這意味著 Google 不僅掌握著使用者的搜尋行為數據,更掌握了使用者在瀏覽網頁時的行為數據,這些數據都可能被用來影響搜尋結果。
揭秘 Google 搜尋系統背後的架構
Google 搜尋系統並非一個單一的演算法,而是由許多相互聯繫的微服務 (Microservice) 組成。這些微服務就像一個精密運作的機器,共同處理著從爬取網頁、索引內容、評估內容品質到呈現搜尋結果的每一個環節。這次外洩的文件,讓我們得以一窺這些微服務的內部結構,了解 Google 搜尋系統的複雜性和精妙設計。
Spanner 架構
Google 搜尋系統背後,是強大的 Spanner 架構。Spanner 是一個分布式數據庫系統,能夠將全球各地的伺服器整合為一體,實現無限擴展的儲存和計算能力。這讓 Google 能够處理海量的網頁數據,並確保搜尋結果能快速被生成。
調整器
除了主要的排名演算法之外,Google 還使用了被稱為「調整器」的微服務,來對搜尋結果進行細微的調整。調整器可以在初始排名 (Initial Ranking) 完成後,根據特定的條件和規則,對搜尋結果的順序進行微調,例如根據內容新鮮度、使用者行為、內容品質等因素進行調整。調整器就像一個精密的旋鈕,可以微調搜尋結果,使其更符合使用者的需求。
關鍵排名系統
外洩文件揭露了許多關鍵的排名系統,它們各司其職,共同完成 Google 搜尋任務。
爬取 (Crawling)
- Trawler:負責爬取網頁,將網路上的資訊納入 Google 的數據庫。
索引 (Indexing)
- Alexandria:核心索引系統,負責儲存和管理所有索引的網頁數據。
- SegIndexer:將網頁分層到索引中不同層級的系統,例如根據重要性、更新頻率等因素進行分類。
- TeraGoogle:用於儲存長期存放在硬碟上的文檔的輔助索引系統。
呈現 (Rendering)
- HtmlrenderWebkitHeadless:負責渲染 JavaScript 頁面的系統。
處理 (Processing)
- LinkExtractor:從頁面中提取連結的系統。
- WebMirror:負責管理重複網頁的系統。
排名 (Ranking)
- Mustang:主要的評分、排名和服務系統,負責為每個網頁計算排名分數。
- Ascorer:主要的排名演算法,在任何重新排名調整之前對頁面進行排名。
- NavBoost:根據使用者點擊數據來調整排名的系統。
- FreshnessTwiddler:根據內容的更新時間來調整排名的系統。
服務 (Serving)
- Google Web Server:和 Google 前端互動的伺服器,負責接收數據並顯示給使用者。
- SuperRoot:Google 搜尋的大腦,負責發送消息給 Google 伺服器,並管理重新排名和結果呈現的後處理系統。
- SnippetBrain:負責為搜尋結果生成摘要的系統。
- Glue:負責將不同類型的搜尋結果整合在一起的系統,例如產生同時有網頁、影片、圖片等的結果頁。
- Cookbook:負責生成排名信號的系統,這些信號可能是被動態創建的。
這些只是 Google 搜尋系統中的一部分的微服務,它們相互配合,共同確保搜尋結果的準確性、相關性以及保障好的使用者體驗。
SEO的關鍵發現
Google 的內部文件外洩,也迫使我們必須重新思考既有的 SEO 策略,以下我會分享身為SEO從業人員的角度,我們得到了什麼樣的資訊。
Google重視內容創作者資訊
因為專業知識和權威性非常難量化,所以很多人質疑Google是怎麼評估E-E-A-T。因此,我們很難相信作者 (Authorship) 是一個足够有效的信號,而實際上也很少網站會真的使用Author Schema標記。儘管如此,Google確實明確將與網頁相關的作者作為文字儲存。

懲罰/降級
洩漏文件中討論了一系列演算法的扣分機制,包括:
錨點文字與指向網頁不匹配:當連結不匹配它所連到的目標網站時,連結在計算中會被扣分。
搜尋結果頁降級:一個信號表明,當從搜尋結果頁中(SERP)觀察到使用者“可能”對網頁不滿意 (這很可能是通過點擊來衡量的)時,網頁會因此被降級。
網站導覽降級:意思是不良的站內導覽或使用者體驗問題,會造成網頁被進行扣分。
完全匹配網域降級:2012年末,Matt Cutts宣布,使用關鍵字作為網域名將不會像以前那樣有效。而文件中確實發現,有一個專門針對它的扣分機制。
地點降级:這表明Google嘗試將頁面與地點相關聯,並據此進行排名。
色情降級:很明顯,意思是對含有色情內容的網頁扣分。
索引層級影響連結價值
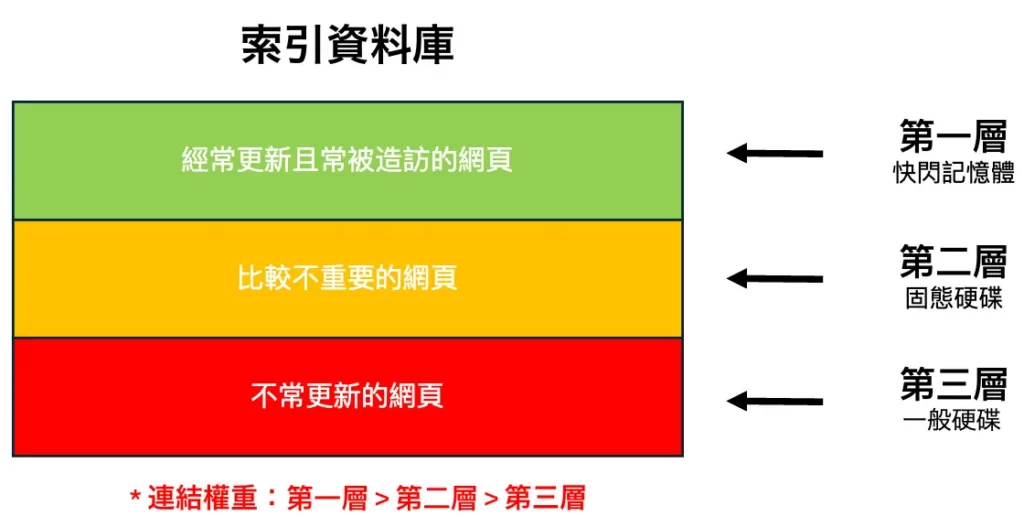
一個叫做 sourceType 的指標顯示了網頁被索引的位置與其價值之間的關係。簡單來說,Google 的索引被分為不同的層級,其中最重要的是定期更新和常被拜訪的網頁,在這類層級的內容會被儲存在快閃記憶體中。不太重要的內容將被儲存在固態硬碟上,而不太定期更新的內容儲存在一般的硬碟上。
層級越高,給出的連結就越有價值。被定義是「新鮮」的網頁也是被認為是高品質的訊號。也就是說,你會希望你的連結都來自於新鮮或是被分類在頂層的頁面。
這解釋了為什麼從排名很高的貨新聞網頁獲得連結時,所連到的網頁會獲得更好的排名。這也顯示了,數位公關 (Digital Public Relation) 的重要性。

垃圾連結信號
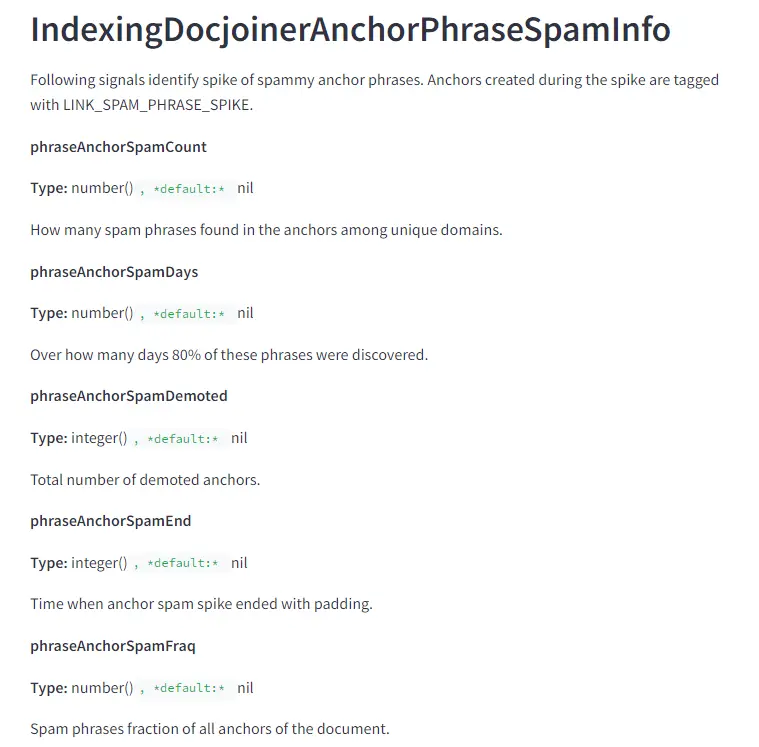
文件也透露 Google 有一項針對偵測連結突然爆增的指標。Google 實際上能夠透過 phraseAnchorSpamDays 這個功能,計算連結建立的速度及頻率。Google可以使用這些數據將特定時間獲得的連結數量與整體趨勢進行比較,懲罰那些違反垃圾連結政策的內容創作者。
分析網頁時,Google只會評估最新的前20個版本
Google的檔案系統能夠像 Wayback Machine 一樣,隨著時間推移,儲存多個網頁的版本。也就是說,Google會永遠保留已被索引的內容。
這就是我們沒辦法透過將網頁重新導向到一個無關的網頁,並期望連結權重傳遞到指向網頁的原因。
當他們通過檢索來比較版本時,他們只考慮頁面的最新的20個版本。 因此,如果你需要把網頁在 Google 上「洗白」,你需要多次更改網頁,並讓它們被索引多次。
首頁PageRank被套用於所有網頁
每個網頁都與其網站首頁 PageRank 相關聯。當發布新的網頁時,首頁的 PageRank 分數會暫時成為新網頁的替代分數,直到它獲得自己的分數為止。

首頁信任度
Google 根據他對首頁的信任程度來評估連結的價值。不過,我們還是應該專注於連結的品質和相關性,而不是數量。

Font Style 很重要
在過去有人刻意將文字加粗、加上底線或者讓某些段落看起來更大,讓它們看起來更重要。以往,這樣的做法其實沒辦法證明對 SEO 是有效的,但現在這份內部文件卻發現 Google 確實有在追蹤網頁內術語的字體大小,而且他們同樣也追蹤錨點文字的字體。
Google讀取的網頁內容有限
Google會計算網頁內 HTML 標籤的數量,以及正文中的總字數與標籤的比例。文件也提到在 Mustang 系統中,可以被讀取的標籤數是有限的,因此這進一步告訴了我們,內容創作者應該把最重要的內容放在越前面越好。

短內容可以被用來評估原創性
OriginalContentScore 指標表明,短內容可以被用來評估內容原創性。這可能也可以說明 Google 並不總是用字數來認定 Thin Content 的原因。

網頁標題仍然很重要
文件表明 Google 使用一個名為 titlematchScore 的指標。用來確認網頁標題與查詢字詞匹配的程度,由此可見 Google 仍然很重視標題。這也是為什麼很多人建議將目標關鍵字放在最前面的原因。

日期非常重要
Google 非常重視新鮮的搜尋結果,文件中多次說明了它嘗試將日期與頁面進行相關聯。
bylineDate – 這是網頁面明確設定的日期。
syntacticDate – 這是從URL或標題中提取的日期。
semanticDate – 這是從頁面內容中推斷出的日期。
最好的做法是讓網頁內關於日期的資訊保持一致,包括在網站訪客可視的地方、結構化資料、頁面標題、XML網站地圖。假設,你的URL中的日期與頁面其他地方的日期不一致,這很可能會導致較低的內容分數。
結論
在面對 Google 演算法的複雜性和不斷變化,SEO從業者需要制定合理的目標和策略,而不是盲目地追求排名。要了解目標市場和使用者的需求,並根據這些需求制定精準的 SEO 策略,以達到預期效果。 外洩文件所揭露的資訊,不僅僅是關於 Google 演算法的秘密,更是一份全新的SEO 指南。它提醒我們,SEO 的核心依然是創造出優秀的內容,為使用者提供良好的體驗,並與 Google 的演算法保持一致。
