什麼是 Knowledge-Based Trust?
我們每天都接觸到海量的網路資訊,不過這些資訊的品質良莠不齊,真假難辨。因此學會評估網路資訊的可信度對 Google 來說變得至關重要。
傳統的網頁排名方法 (例如,PageRank),主要依賴於網頁的受歡迎程度和反向連結數量,卻忽略了資訊本身的準確性。為了解決這個問題,Google提出了一個名為 Knowledge-Based Trust 的專利,簡稱 KBT 的全新評估方法,以下我們就來一起探討 KBT 的運作方式。
KBT 的運作方式
這項專利主張,網頁的可信度是取決於其所提供事實資訊的準確性。換句話說,一個網頁如果很少出現錯誤資訊,那麼它就會被認為是更可靠的。KBT評估網站可信度的過程主要分為以下幾個步驟。
事實資訊提取
首先,資訊提取工具會掃描和分析大量的網頁,自動收集大量的”事實“數據。這些數據以『三元組 (Semantic Triple)』的形式呈現,每個三元組包含主語 (Subject)、謂語 (Predicate)和賓語 (Object)。
舉例來說,「中華民國位於亞洲東部」這句話,可以轉換成以下三元組:(中華民國, 位於, 亞洲東部)。同一主題的事實資訊可以從不同的網站提取,提供更多元的依據來評估資訊的正確性。
錯誤識別
提取到數據之後,系統會自動分析資訊是否是網頁本身存在的事實錯誤,還是資訊提取工具在收集數據過程中產生的錯誤。為了區分是哪一種錯誤,KBT 採用了多層機率模型 (Multi-layer Probabilistic Model),以下用一個簡單的例子解釋。
假設我們有一群偵探要根據證詞來判斷真相,證詞來自目擊者 (網站) 和記錄員 (資訊提取系統)。問題是,目擊者和記錄員都可能犯錯,目擊者可能記錯現場發生的狀況,記錄員也可能抄寫錯誤。
而 KBT 的機率模型就像一個聰明的偵探,它不會單純計算有多少證詞支持某個說法,而是會同時考慮:
證詞來源的可靠度: 一個經常提供準確資訊的目擊者 (網站),其證詞的可信度自然更高。
記錄員的準確率: 一個很少出錯的記錄員 (資訊提取系統),其記錄的資訊也更可信。
迭代式演算法
為了更精確估計 KBT 分數,系統更近一步採用了一種迭代式的演算法。
再次以偵探 (KBT 系統)、目擊者 (網站) 和紀錄員 (資料提取工具) 為例,如果一個說法得到很多可靠目擊者的支持,但一個平時很準確的記錄員卻記錄了相反的資訊,KBT 系統就會懷疑這個記錄員可能出錯了,並降低對該記錄員的信任度。
同理,如果多個或權威網站都陳述相同的事實,而某一個網站所述的事實與大多數或跟權威網站不同,那系統也會將該網站的信任度降低。
透過這種迭代推理的方式,KBT 系統就能夠更準確識別出哪些資訊是網站本身的錯誤,哪些是資訊提取過程中的錯誤,從而更準確評估網站的可信度。
動態調整
KBT 系統會根據網頁資訊量的多寡,靈活調整分析的精細程度。對於資訊量較少的網頁,KBT 系統會將其與其他主題相關的網頁資訊合併分析,藉此擴大樣本數,提高評估結果的穩定性。
反之,對於資訊量極大的網頁,KBT 系統則會將其拆分成多個部分,分別進行分析。這樣可以避免單一網頁過於龐大的資訊量拖累整體的運算速度,同時也能維持評估結果的精準度。
透過這種動態調整資訊粒度的方式,KBT 系統能夠更有效率地處理海量的網頁數據,並在可接受的時間內完成對網站信賴度的評估。
可信度計算
基於前幾個步驟,每個網站會得到一個 KBT 分數,代表其整體的可信度。網站中事實錯誤越少,無論是網站本身的錯誤還是資料提取過程中的錯誤,其 KBT 分數就越高。KBT 分數本質上是每個事實資訊正確概率的加權平均值。這意味著,網站中準確資訊的比例越高,其可信度也就越高。
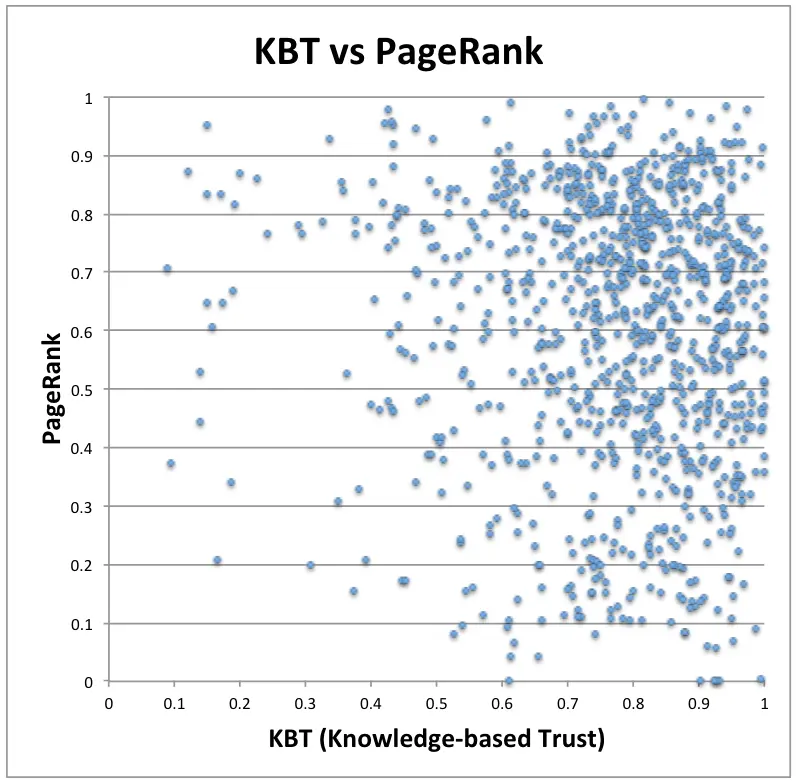
KBT vs PageRank
這項學術研究中發現到,PageRank 和 KBT 之間沒有強烈的相關性。在圖表上的數據呈現出分散的狀態,沒有明顯的規律或趨勢。換句話說,一個網站的受歡迎程度並不能代表其資訊的準確性。
我們可以在圖表中發現 KBT 高但 PageRank 低的網站 (位於圖表右下方),這些網站可能是提供準確資訊但尚未獲得廣泛關注的專業網站。相反,也存在 PageRank 高但 KBT 低的網站 (位於圖表左上方),這些網站可能是社群媒體或八卦網站等熱門平台,其資訊的準確性比較難保證。
因此,我們可以總結這種缺乏相關性的現象,突顯了 PageRank 和 KBT 衡量的是網站的不同面向,這兩項指標是相互獨立且互補的評估指標,結合使用可以更全面評估網頁的可信度。
SEO 的應對策略
KBT 的出現改變搜尋引擎評估網站的方式,將重點從基於反向連結數量轉移到事實本身的準確性。如果 KBT 是重要的排名因素,我們將需要更加重視內容的準確性和可靠性。
為了讓網頁資訊都能被 KBT 系統成功提取,可以考慮使用結構化資料 (Structured Data) 的方式標記事實數據,降低提取資料發生錯誤的機率。同時,我們還需要確保分享出來的資訊是有憑有據且正確的,建議可以引用可靠的資訊來源或提出數據佐證,定期審查網站內容,找出並更新錯誤或過時的資訊。
