近年來,生成式 AI(Generative AI)發展一日千里,其強大的能力不斷改寫著我們對科技的認知界限。從 OpenAI 推出的 ChatGPT 到 Google 推出的 Google Bard,都預示著這項技術將在各個領域掀起革新浪潮。然而,如果要真正理解這些 AI 應用背後的奧秘,就必須深入了解 Transformer 模型和 BERT 模型 —— 這兩項技術正是近年來自然語言處理 (Natural Language Processing) 領域的重大突破。
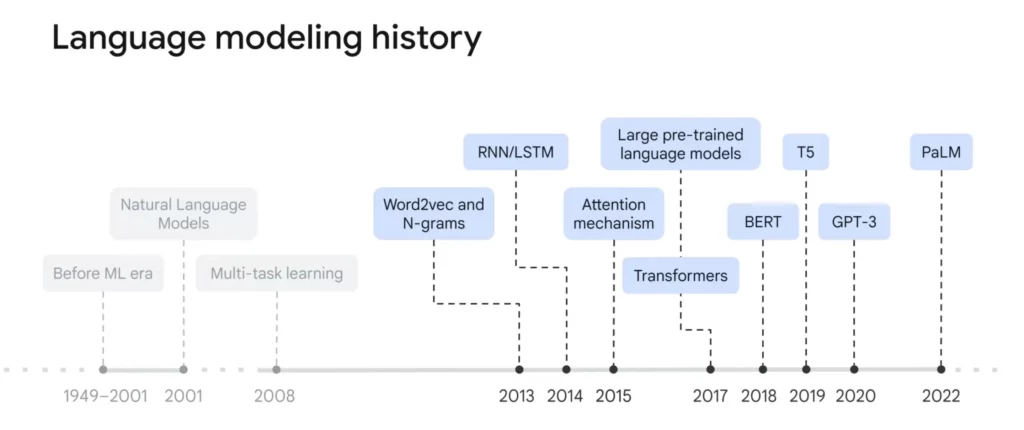
語言模型的演進:從單詞到語境理解
語言模型的發展歷程,如同人類學習語言的過程般循序漸進。試想孩童時期,我們先認識單個詞彙,接著學習組合詞語,最終理解句子和段落,並領會其中蘊含的情感和邏輯。而語言模型的發展也經歷了類似的階段。
早期的語言模型,例如 n-gram 和 Word2Vec,主要聚焦於單詞上,將每個詞彙轉化為一個向量。然而,這種方法忽略了一個關鍵因素:語境。 就像 “bank” 這個詞,可以用來表達 “河岸” 和 “銀行”,儘管拼寫相同,卻代表著截然不同的含義。
2013 年,神經網路的引入,特別是遞迴神經網路 (RNN) 和 長短期記憶網路 (LSTM),為語言模型帶來了革命性的變化。RNN 和 LSTM 擅長處理序列數據,它們能夠學習詞彙之間的關聯性,以及句子中詞彙的順序關係,並在機器翻譯和檔案分類等任務上取得了顯著的成果。
然而,RNN 和 LSTM 模型並非完美無缺。它們在處理長句子時,容易出現一些問題,導致模型難以有效捕捉到句子中長距離詞彙之間的關係。試想一篇長篇文章,開頭提到一個人物,結尾才再次出現,此時RNN 和 LSTM 很可能無法將兩者聯繫起來,導致理解偏差。
Transformer 的革新
2015 年,注意力機制 (Attention Mechanism) 的橫空出世,徹底改寫了語言模型的格局。Transformer 模型,誕生於 2017 年的論文 “Attention is All You Need“,成為 NLP 領域的里程碑,也為 BERT 模型的發展奠定了堅實的基礎。
Transformer 模型的核心正是注意力機制,它賦予了模型如同人類般的「專注力」,讓模型能夠精準捕捉到句子中關鍵詞彙和訊息,並理解它們之間的關係。試想我們閱讀文章時,並非逐字逐句去理解,而是會根據上下文,選擇性地關注關鍵詞彙和句子,並理解它們之間的邏輯關係。Transformer 模型的注意力機制,就如同我們的大腦,能夠在訊息中抽絲剝繭,抓住重點。
Transformer 模型的出現,打破了傳統 RNN 模型的局限性,獲得以下優勢:
Parallel Processing: Transformer 架構讓模型同時處理句子中的所有詞彙,大幅提升運算效率。傳統的 RNN 模型則需要依從順序處理詞彙,在面對長句子時效率較差。
Long-range Dependencies: Transformer 模型能夠輕鬆捕捉到句子中遠距離詞彙之間的關聯,即使兩個詞彙相隔甚遠,Transformer 也能準確理解它們的關係,這是 RNN 模型難以企及的。
Transformer 模型的運作原理
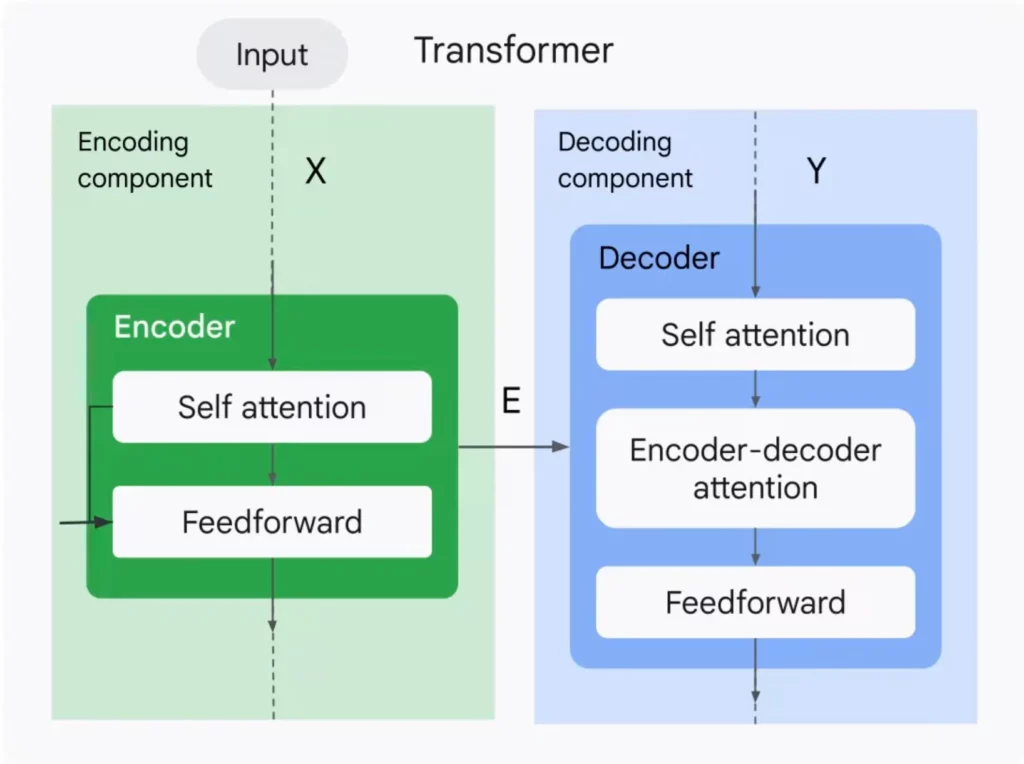
Transformer 模型由編碼器 (Encoder) 和解碼器 (Decoder) 兩部分組成,它們如同語言轉換的橋樑,將輸入的文字訊息轉化為機器可理解的向量,並最終生成目標輸出。
編碼器 (Encoder)
編碼器負責將輸入的句子轉換成一個富含語義訊息的向量。它由多層相同的編碼器單元堆疊而成,每個編碼器單元都包含兩個關鍵組成:
自我注意力層 (Self-Attention Layer)
這一層賦予了模型理解詞彙之間關係的能力。它會計算每個詞彙與句子中其他詞彙的相關性,並根據相關性為每個詞彙分配不同的權重,最終形成一個包含上下文訊息的詞彙表示。
想像你正在讀一篇長篇文章,要理解文章的主旨,你需要同時考慮文章中所有句子之間的關係,哪些句子更重要,哪些句子互相呼應。
自注意力層就像你閱讀文章時的大腦一樣,它能同時考慮輸入的資料中所有部分之間的關係,並決定哪些部分更重要。它能找出資料中最重要的部分,並加強這些部分的權重,同時減弱其他不重要部分的權重。
前饋神經網路層 (Feedforward Neural Network Layer)
這一層則負責對每個詞彙的向量進行非線性轉換,提取更深層次的語義訊息,讓模型的理解更加深入和準確。
簡單來說,前饋神經網路層就像一個處理資訊的「工廠」。它接收資料,經過一連串的計算和轉換,然後將處理後的資訊傳遞到下一層。
想象一個工廠生產汽車:
輸入層 (Input Layer): 就像工廠的原料,例如鋼鐵、塑膠等。
隱藏層 (Hidden Layers): 就像工廠的生產線,將原料加工成零件,再組裝成汽車。
輸出層 (Output Layer): 就像工廠的成品,也就是最終的結果,例如一輛完整的汽車。
解碼器 (Decoder)
解碼器則根據編碼器生成的向量,生成最終的輸出結果,例如翻譯後的句子、文件摘要、或者問題的答案。它同樣由多層技術組成,解碼器除了包含 Self-Attention Layer 和 Feedforward Neural Network Layer 之外,還包含編碼器-解碼器注意力層 (Encoder-Decoder Attention Layer)。
編碼器-解碼器注意力層的目標是讓解碼器能夠更關注編碼器生成的向量中與當前輸出詞彙『高相關』的部分。簡而言之,這一層就像一個橋樑,連接了兩個語言系統,讓它們能夠相互理解,並產生更精准、更高品質的翻譯結果。
Google BERT
BERT (Bidirectional Encoder Representations from Transformers) 是 Google 在 2018 年提出的 Pre-trained Transformer 模型,它可以被視為站在巨人肩膀上的 NLP 新星。BERT 是一個只使用編碼器 (Encoder) 的模型,Google用海量的資料對它進行訓練,學習到了豐富的語言知識,並在多項 NLP 應用中都展現出了驚人的效果,包含:Google 搜索、文件分類、翻譯、問答系統、文字生成等。
預測詞彙,理解語義
BERT 的訓練過程主要包含以下兩個關鍵步驟。
掩碼語言模型 (Masked Language Modeling)
在這個步驟中,BERT 會隨機掩蓋輸入句子中的部分詞彙,並嘗試根據上下文訊息預測被掩蓋的詞彙。例如,輸入句子 “The man went to the [MASK] to buy a [MASK]”,BERT 需要根據上下文推斷出 [MASK] 應該填入 “store”及”gallon”。這個步驟訓練了 BERT 對詞彙之間關係的理解能力,以及根據上下文推斷詞彙含義的能力。
不過同樣需要非常注意遮掩的詞彙數量,如果遮掩過少詞彙,會造成訓練成本過高;然而遮掩過多詞彙,會造成上下文的資訊不足。

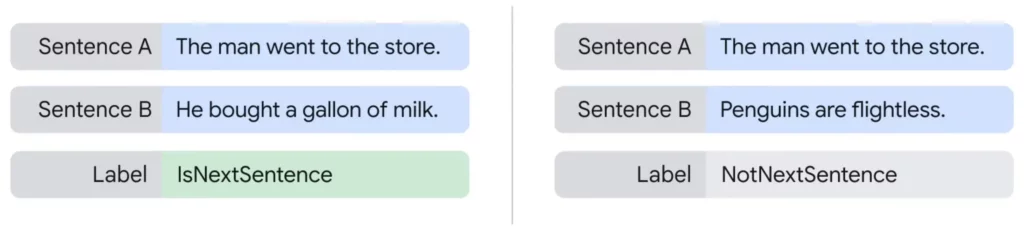
下一句預測 (Next Sentence Prediction)
在這個步驟中,BERT 會接收兩個句子作為輸入,並判斷第二個句子是否是第一個句子的下一句。例如,輸入兩個句子:”The man went to the store.” 和 “He bought a gallon of milk.”,BERT 需要判斷第二個句子是否緊接著第一個句子。這個步驟訓練了 BERT 對句子之間關係的理解能力,以及如何理解句子之間的邏輯。
BERT 帶來的改變
有了 BERT,Google 搜尋變得更加聰明。它不再只依靠關鍵詞匹配,而是能夠真正理解你的搜尋意圖,你可以嘗試用更完整的句子描述你的搜尋需求,看看 BERT 能否理解你的意圖並提供更精准的結果。
BERT 是一個正在不斷進化的技術,它將繼續提升 Google 搜尋的能力,讓搜尋變得更加智能化、更符合人性。
